Excel количество уникальных значений в столбце

В большинстве примеров, представленных в предыдущем разделе, используются функции и формулы, которые подсчитывают количество ячеек, удовлетворяющих определенным условиям. В этом разделе рассмотрены более сложные примеры подсчета ячеек рабочего листа с применением дополнительных формул, включающих различные виды условий.
Подсчет ячеек с помощью функции СЧЁТЕСЛИ
Функцию СЧЁТЕСЛИ чаще всего используют в формулах, ограниченных одним условием. Функция СЧЁТЕСЛИ принимает два аргумента.
• Диапазон. Содержит значения, определяющие, включать ли конкретную ячейку в расчет. • Логическое_условие. Определяет, включать ли конкретную ячейку в расчет.
В таблице представлены некоторые примеры использования функции СЧЁТЕСЛИ. Приведенные формулы обращаются к диапазону Данные. С помощью условия можно добиться большой гибкости возвращаемых данных. Обратите внимание, что аргумент Логическое_условие может представлять собой любой тип данных: константы, выражения, функции, ссылки на ячейку и даже групповые символы (* и ?).

Подсчет ячеек, удовлетворяющих множеству условий
Во многих случаях формула должна учитывать только те ячейки, которые удовлетворяют двум или более условиям. Выбор условий основывается на ячейках, которые уже подсчитаны, или на строго определенном диапазоне ячеек.
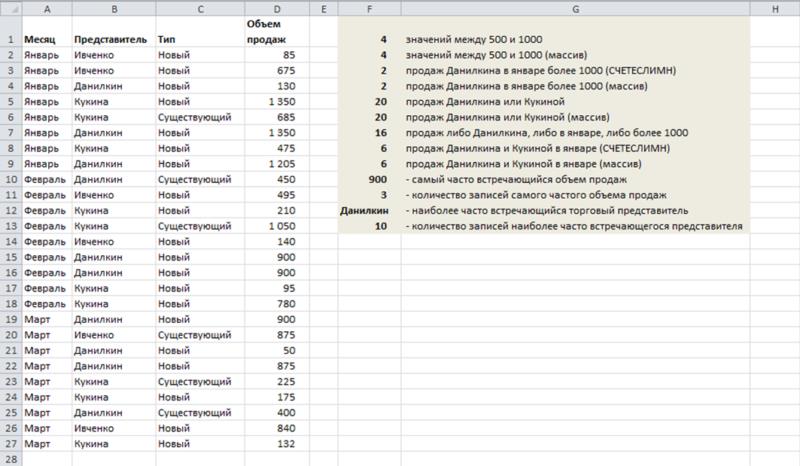
Все примеры этого раздела приведены для простого рабочего листа, показанного на рисунке, в котором в столбцах Месяц, Представитель и Тип содержатся данные о продажах товара фирмой. Диапазоны ячеек данного рабочего листа имеют имена, соответствующие значениям, введенным в строку 1.
Новинка
Некоторые примеры этого раздела используют функцию СЧЁТЕСЛИМН, введенную в версии Excel 2007. В разделе также будут представлены альтернативные версии формул, которые нужно использовать, если создаваемую рабочую книгу требуется совместно использовать с теми, у кого установлены предыдущие версии Excel.
Использование условия И
Функция СЧЁТЕСЛИМН принимает пары аргументов. В пару входят диапазон условия и условие. Количество пар не ограничено. Логическая операция И реализуется благодаря тому, что функция учитывает ячейку, только если истинны все пары. Используя условие И, можно подсчитать все ячейки диапазона, соответствующие определенным условиям. Типичным примером использования этого условия можно считать формулу, с помощью которой подсчитывается количество значений, содержащихся в пределах определенного числового диапазона. Предположим, что необходимо подсчитать ячейки, которые отображают значения большие 100 и меньшие или равные 200. Функция СЧЁТЕСЛИМН принимает следующий вид:
=СЧЁТЕСЛИМН(Объем;“>100”;Объем;“<=200”)
До выхода в свет Excel 2007 вам пришлось бы использовать формулу следующего вида:
=СЧЁТЕСЛИ(Объем;“>100”)-СЧЁТЕСЛИ(Объем;“>200”)
Возможно, вид данной формулы вводит в заблуждение. Несмотря на то, что ее цель состоит в подсчете значений, которые меньше или равны 200, но больше ста, в формуле написано “>200”. Объяснение простое: знак “минус” означает, что эти ячейки вычитаются из общего количества. Существует еще один метод, в котором используется формула массива (этот метод проще предыдущего):
{=СУММ((Объем>100)*(Объем<=200))}
При вводе формулы массива не забывайте нажимать <Ctrl+Shift+Enter> вместо <Enter>; также не вводите вручную фигурные скобки – они будут вставлены автоматически.
Условия подсчета можно задать не только для суммируемых, но и для других ячеек. Например, можно подсчитать количество продаж в ячейках, соответствующих следующим условиям:
• месяц – январь и • представитель – Данилкин и • сумма больше 1000.
Следующая формула возвращает количество ячеек массива, соответствующих всем трем условиям:
=СЧЁТЕСЛИМН(Месяц;“Январь”;Представитель;“Данилкин”;Объем;“>1000”)
В качестве альтернативы можно использовать следующую формулу массива:
{=СУММ((Месяц=“Январь”)*(Представитель=“Данилкин”)*(Сумма>1000))}
Использование условия ИЛИ
Чтобы подсчитать количество ячеек с помощью условия ИЛИ, иногда задействуется несколько функций СЧЁТЕСЛИ. Например, следующая формула подсчитывает количество значений 1, 3 и 5 в диапазоне Данные:
=СЧЁТЕСЛИ(Данные;1)+СЧЁТЕСЛИ(Данные;3)+СЧЁТЕСЛИ(Данные;5)
Функция СЧЁТЕСЛИ также используется в формуле массива. Например, формула массива, приведенная ниже, возвращает тот же результат, что и предыдущая формула.
{=СУММ(СЧЁТЕСЛИ(Данные;{1;3;5}))}
Если условие ИЛИ применяется не к подсчитываемым ячейкам, а к ячейкам другого диапазона, функция СЧЁТЕСЛИ работать не будет. Вернемся снова к рисунку выше и предположим, что необходимо подсчитать количество продаж, соответствующих следующим условиям:
• месяц – январь или • представитель – Данилкин или • объем – более 1000.
Следующая формула массива возвращает правильный результат подсчета:
{=СУММ(ЕСЛИ((Месяц=“Январь”)+(Представитель=“Данилкин”)+(Объем>1000);1))}
Одновременное использование условий И и ИЛИ
При подсчете ячеек условия И и ИЛИ можно комбинировать. Предположим, что требуется подсчитать продажи, удовлетворяющие следующим условиям:
• месяц – январь и • представитель Данилкин или • представитель Кукина.
Следующая формула массива возвращает объем продаж, соответствующих этим условиям:
=СЧЁТЕСЛИМН(Месяц;“Январь”;Представитель;“Данилкин”)+ СЧЁТЕСЛИМН(Месяц;“Январь”;Представитель;“Кукина”)
Так как в данном случае в аргументах функции приходится повторять операцию “И”, использование СЧЁТЕСЛИМН может привести к созданию длинных формул с множеством критериев. Когда список критериев велик, удобнее использовать формулы массивов. К примеру, следующая формула массива вернет тот же результат, что и предыдущая:
{=СУММ((Месяц=“Январь”)*ЕСЛИ((Представитель=“Данилкин”)+ (Представитель=“Кукина”);1))}
Подсчет наиболее часто встречающихся записей
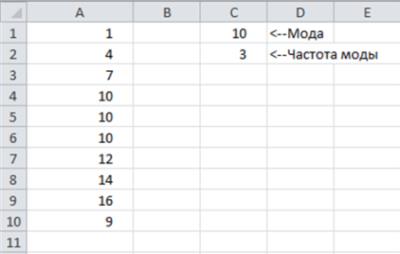
Функция МОДА возвращает значение, наиболее часто встречающееся в диапазоне ячеек. На рисунке показан рабочий лист, содержащий диапазон ячеек А1:А10 (с именем Диапазон1). Формула, приведенная ниже, возвращает значение 10, поскольку это значение в данном диапазоне ячеек встречается наиболее часто.
=МОДА(Диапазон1)
Эта формула возвращает значение #Н/Д, если диапазон, указанный в ее аргументе, не содержит дублирующихся значений.
Чтобы подсчитать количество наиболее часто встречающихся в заданном диапазоне значений (иными словами, частоту моды), воспользуйтесь следующей формулой:
=СЧЁТЕСЛИ(Диапазон1;МОДА(Диапазон1))
Представленная формула возвращает значение 3, поскольку значение моды (10) встречается в диапазоне Диапазон1 три раза.
Имейте в виду, что функция МОДА работает только с числовыми значениями. В том случае, если заданная ячейка содержит текст, функция ее игнорирует. Для того чтобы найти текстовую строку, наиболее часто встречающуюся в заданном диапазоне, используйте формулу массива.
Чтобы подсчитать количество элементов, наиболее часто встречающихся в заданном диапазоне Данные (речь идет и о тексте, и о числовых значениях), используйте следующую формулу массива:
{=МАКС(СЧЁТЕСЛИ(Данные;Данные))}
Представленная ниже формула массива работает подобно функции МОДА, за исключением того, что в данном случае могут использоваться как числовые, так и текстовые значения.
{=ИНДЕКС(Данные;ПОИСКПОЗ(МАКС(СЧЁТЕСЛИ(Данные;Данные)); СЧЁТЕСЛИ(Данные;Данные);0))}
Предупреждение
Если существует несколько значений, встречающихся с одинаковой максимальной частотой, данная формула вернет первое из них.
Подсчет количества вхождений заданного текста
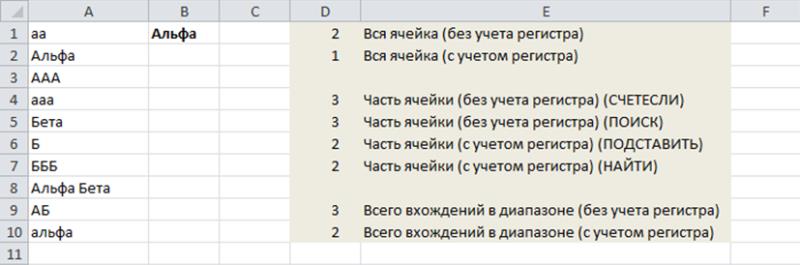
В этом разделе продемонстрированы различные способы подсчета количества экземпляров определенной строки символов или текстовой строки в заданном диапазоне ячеек. Все примеры данного раздела приведены для рабочего листа, показанного на рисунке, который в диапазоне ячеек A1:А10 (диапазон с именем Диапазон2) содержит различную текстовую информацию. Ячейка В1 отображает искомую фразу (диапазон Текст).
Содержимое всей ячейки
Чтобы подсчитать количество ячеек, которые содержат только значение, введенное в ячейку Текст (и не содержат никаких других символов), воспользуйтесь функцией СЧЁТЕСЛИ. Для этого создайте следующую формулу:
=СЧЁТЕСЛИ(Диапазон2;Текст)
Например, если ячейка Текст содержит текстовую строку “Альфа”, формула возвращает значение 2, поскольку этот текст находится в двух ячейках диапазона Диапазон2. Обратите внимание, что данная формула не учитывает регистр символов и воспринимает содержимое ячеек А2 и А10 как идентичные текстовые строки. В то же время содержимое ячейки А8 данная формула игнорирует.
Следующая формула массива подобна предыдущей, за исключением того, что учитывается регистр символов:
{=СУММ(ЕСЛИ(СОВПАД(Диапазон2;Текст);1))}
Часть содержимого ячейки
Чтобы подсчитать количество ячеек, которые содержат строку, включающую в себя строку ячейки Текст в качестве подстроки, используйте следующую формулу:
=СЧЁТЕСЛИ(Диапазон2;“*”&Текст&“*”)
Например, если в ячейке Текст находится текст Альфа, данная формула возвращает значение 3, поскольку в диапазоне Диапазон2 текст Альфа присутствует в трех ячейках: А2, А8 и А10. Обратите внимание, что регистр в данном случае не учитывается.
Альтернативная формула массива, использующая функцию ПОИСК, немного длиннее:
{=СУММ(ЕСЛИ(НЕ(ЕОШИБКА(ПОИСК(Текст;Диапазон2)));1))}
Функция ПОИСК возвращает ошибку, если искомый текст не найден. В приведенном примере подсчитываются все ячейки, в которых не была сгенерирована ошибка. Так как функция ПОИСК не чувствительна к регистру символов, то же можно сказать и о формуле.
Если нужно подсчитать вхождения с учетом регистра символов, можете использовать следующую формулу массива:
{=СУММ(ЕСЛИ(ДЛСТР(Диапазон2)- ДЛСТР(ПОДСТАВИТЬ(Диапазон2;Текст;“”))>0;1))}
Если ячейка Текст содержит слово “Альфа”, предыдущая формула возвращает значение 2, поскольку данная текстовая строка встречается в двух ячейках диапазона (А2 и А8).
Подобно функции ПОИСК, функция НАЙТИ возвращает ошибку, если искомый текст не найден. Таким образом, альтернативную версию предыдущей формулы можно записать в следующем виде:
{=СУММ(ЕСЛИ(НЕ(ЕОШИБКА(НАЙТИ(Текст;Диапазон2)));1))}
В отличие от ПОИСК, функция НАЙТИ различает регистр символов.
Общее количество экземпляров строки в заданном диапазоне
Чтобы подсчитать общее количество экземпляров строки в заданном диапазоне ячеек, используйте следующую формулу массива:
{=СУММ(ДЛСТР(Диапазон2))- СУММ(ДЛСТР(ПОДСТАВИТЬ(Диапазон2;Текст;“”))))/ДЛСТР(Текст)}
Если ячейка Текст содержит символ Б, данная формула возвращает значение 7 – этот символ есть в семи ячейках заданного диапазона. Имейте в виду, что эта формула учитывает регистр символа. Чтобы игнорировать регистр, используйте следующую измененную формулу массива:
{=(СУММ(ДЛСТР(Диапазон2))-СУММ(ДЛСТР(ПОДСТАВИТЬ(ПРОПИСН(Диапазон2); ПРОПИСН(Текст);“”))))/ДЛСТР(Текст)}
Подсчет количества уникальных значений
Следующая формула массива возвращает количество уникальных значений в диапазоне Интервал:
{=СУММ(1/СЧЁТЕСЛИ(Интервал;Интервал))}
Для полного понимания того, как работает эта формула, вам необходимо усвоить основные принципы работы формул массива. На рисунке показан рабочий лист, содержащий два диапазона ячеек: диапазон А1:А12 (Интервал) и диапазон С1:С12, во все ячейки которого включена следующая формула массива (одна формула скопирована во все 12 ячеек диапазона):
{=СЧЁТЕСЛИ(Интервал;Интервал)}
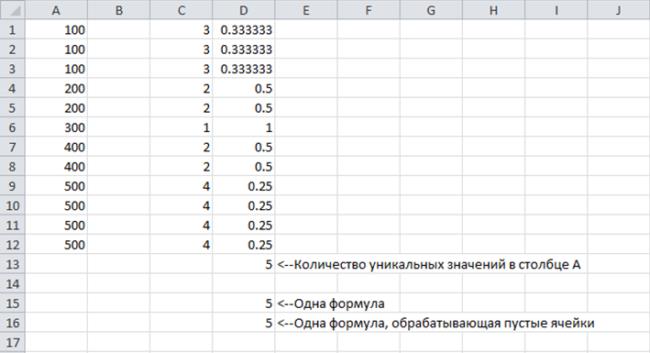
Массив в диапазоне Cl:Cl2 содержит итоги, подсчитанные для каждого значения в массиве Интервал. Например, число 100 появляется в массиве Интервал три раза. Таким образом, каждый элемент массива С1:С12, соответствующий значению 100 в диапазоне Интервал, будет содержать значение 3. Диапазон D1:D12 отображает результаты следующей формулы массива:
{=1/Cl:С12}
Данный массив состоит из значений, полученных путем деления 1 на значения массива в диапазоне ячеек Cl:С12. Например, если какая-либо ячейка исходного диапазона Интервал содержит значение 200, то соответствующая ей ячейка в диапазоне Dl:D12 будет иметь значение 0,05.
Суммирование значений диапазона D1:D12 дает число одинаковых элементов, содержащихся в массиве Интервал. По существу, формула, приведенная в начале этого раздела, создает массив значений в диапазоне ячеек Dl:D12 и суммирует значения этого массива.
Однако эта формула имеет серьезное ограничение: в том случае, если диапазон содержит пустые ячейки, формула возвращает ошибку. Приведенная ниже формула массива решает эту проблему.
{=СУММ(ЕСЛИ(СЧЁТЕСЛИ(Интервал;Интервал)=0;“”; 1/СЧЁТЕСЛИ(Интервал;Интервал)))}
Распределение частот
Главным компонентом процедуры распределения частот является итоговая таблица, которая отображает частоту повторения значений в заданных интервалах. Например, преподаватель школы или ВУЗа может создать распределение частот экзаменационных оценок, т.е. таблицу, в которой отображается количество значений 1, 2, 3 и т.д. Чтобы создать распределение частот, воспользуйтесь одним из следующих инструментов, которые Excel предоставляет в ваше распоряжение:
• функция ЧАСТОТА; • собственная формула; • надстройка “Пакет анализа”; • сводная таблица.
Примечание
Если данные представлены в форме базы данных, для создания распределения частот можно также использовать сводную таблицу.
Функция ЧАСТОТА
Самый простой способ создания таблицы распределения частот в приложении Excel – использование функции ЧАСТОТА. Эта функция возвращает массив, поэтому она всегда должна применяться в формуле массива, введенной в диапазон ячеек.
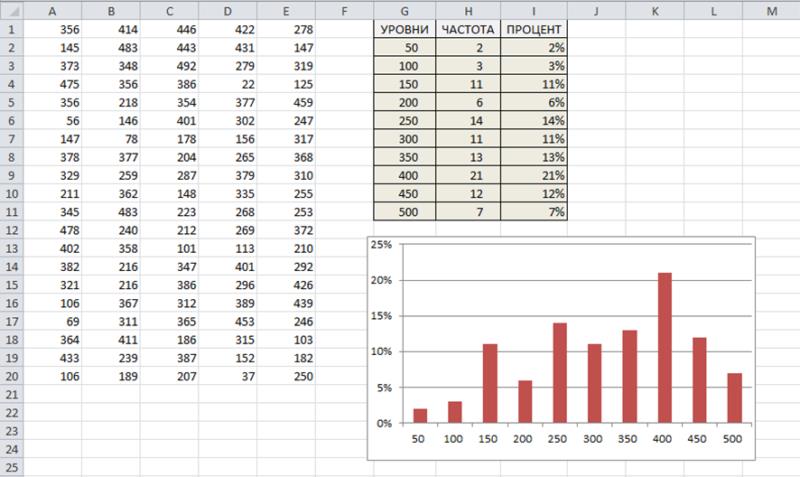
На рисунке в диапазон ячеек A1:Е20 (Диапазон3) введены значения от 1 до 500. Диапазон G2:G11 задает уровни дискретизации (интервалы), используемые в распределении частот. Каждая ячейка этого диапазона представляет собой верхний предел интервала. В данном случае используются интервалы 1-50, 51-100, 101-150 и т.д. Более простой способ создания интервалов рассматривается далее.
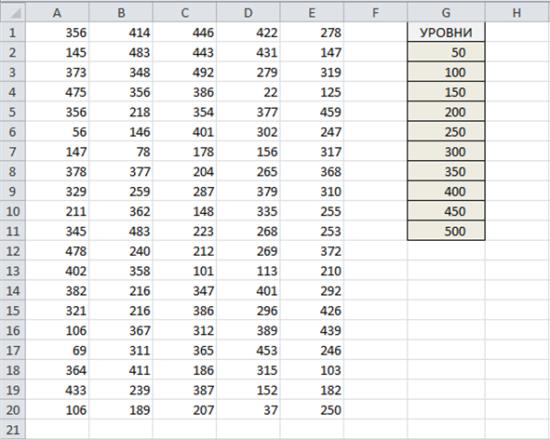
Чтобы создать график распределения частот, выберите диапазон ячеек, значения в которых соответствуют интервалам. После чего введите следующую формулу массива:
{=ЧАСТОТА(Диапазон3;G2:G11))}
Приведенная формула массива подсчитывает количество значений в диапазоне Диапазон3, которые попадают в каждый интервал. Чтобы представить распределение частот в виде процентной зависимости, используйте следующую функцию:
{=ЧАСТОТА(Диапазон3;G2:G11)/СЧЁТ(Диапазон3)}
На рисунке показаны два варианта распределения частот: один в виде числовых значений, а другой – в процентах. Кроме того, здесь показана диаграмма (или гистограмма), созданная на основе полученного распределения частот.
Создание интервалов для распределения частот
Прежде чем приступить к созданию распределения частот в диапазоне значений, нужно определить интервалы. Количество интервалов задает количество категорий в распределении. В большинстве случаев используются интервалы одинаковой длины.
Чтобы создать 10 равномерно удаленных друг от друга уровней дискретизации для значений диапазона Данные, в диапазон, состоящий из 10 ячеек отдельного столбца, введите следующую формулу массива.
{МИН(Данные)+(СТРОКА(ДВССЫЛ(“1:10”))* (МАКС(Данные)-МИН(Данные)+1)/10)-1}
Эта формула создает 10 интервалов на основе значений диапазона Данные. Верхнее значение элемента всегда соответствует максимальному значению интервала.
Чтобы создать большее или меньшее количество интервалов, необходимо использовать другое значение, отличное от 10, а саму формулу массива ввести в диапазон, содержащий такое же количество ячеек. Например, чтобы создать пять интервалов, введите следующую формулу массива в диапазон, состоящий из пяти расположенных вертикально ячеек.
{МИН(Данные)+(СТРОКА(ДВССЫЛ(“1:5”))* (МАКС(Данные)-МИН(Данные)+1)/5)-1}
Использование формул для создания таблицы распределения частот
На рисунке показан рабочий лист, который содержит экзаменационные оценки 50 студентов (столбец В – Оценки). Формулы в столбцах G и Н вычисляют распределение оценок студентов. Минимальные и максимальные баллы для каждого интервала отображаются в столбцах D и Е. Например, экзаменационная оценка, находящаяся в интервале между 80 и 89 (включительно), помещается в столбец В диаграммы.
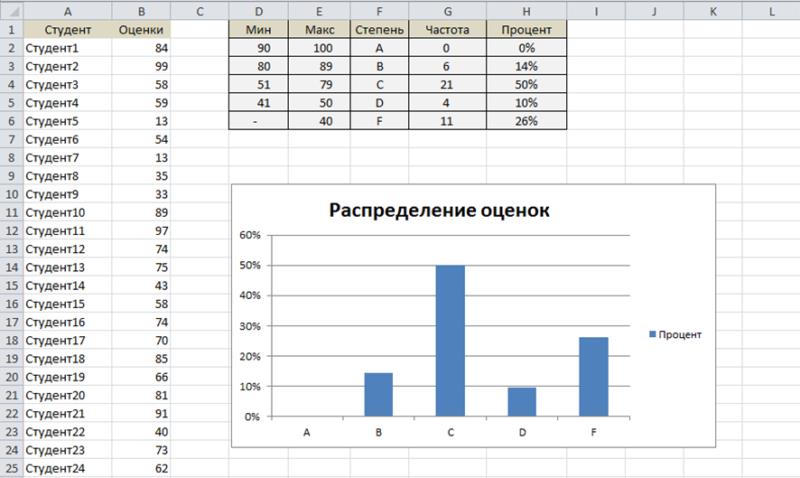
Формула в ячейке G2, приведенная ниже, представляет собой формулу массива, которая подсчитывает количество баллов, относящихся к оценке А.
{=СУММ((Оценки>=D2)*(Оценки<=Е2))}
Формулы в столбце Н вычисляют процентное соотношение оценок. Формула, содержащаяся в ячейке Н2, скопирована в четыре ячейки, находящиеся ниже Н2.
=G2/CYMM($G$2:$G$6)
Использование надстройки “Пакет анализа” для создания таблицы распределения частот
Если в Excel установлена надстройка “Пакет анализа”, то для создания таблицы распределения частот можно использовать инструмент Гистограмма. Перед тем как начать работу с этим инструментом, введите в диапазон необходимые значения предельных уровней интервалов. После этого во вкладке Данные выберите команду Анализ данных. Откроется диалоговое окно Анализ данных. Выберите в списке элемент Гистограмма и щелкните на ОК, после чего на экране откроется диалоговое окно, показанное на рисунке.
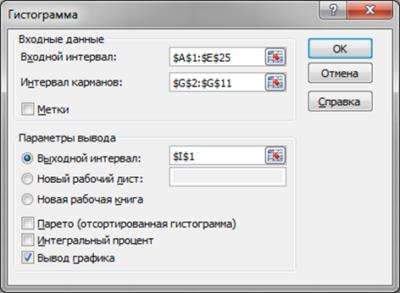
В полях Входной интервал, Интервал карманов и Выходной интервал установите, соответственно, диапазоны входных данных, уровней дискретизации и выходных данных, а затем задайте дополнительные параметры распределения. На рисунке ниже показана диаграмма распределения частот, созданная с помощью диалогового окна Гистограмма.
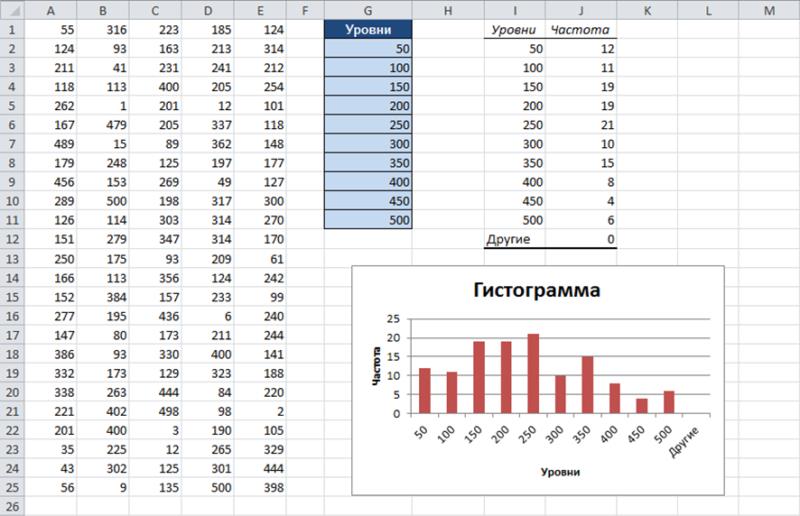
Предупреждение
Учтите, что в данном случае распределение частот состоит из значений, а не формул. Поэтому при внесении изменений во входные данные нужно повторно открыть диалоговое окно Гистограмма, чтобы обновить отображаемые графические результаты.
Установлен ли пакет анализа?
Чтобы проверить, установлен ли в Excel пакет анализа, откройте вкладку Данные. Если на ленте есть группа Анализ, а в ней – кнопка Анализ данных, значит, пакет анализа установлен, а если нет – его нужно установить. Для этого выполните следующие действия.
1. Откройте диалоговое окно Параметры Excel. 2. Выберите вкладку Надстройки. 3. В списке Неактивные надстройки должен быть пункт Пакет анализа. 4. Щелкните на кнопке Перейти. Откроется диалоговое окно Надстройки. 5. Установите флажок Пакет анализа. 6. Щелкните на кнопке ОК.
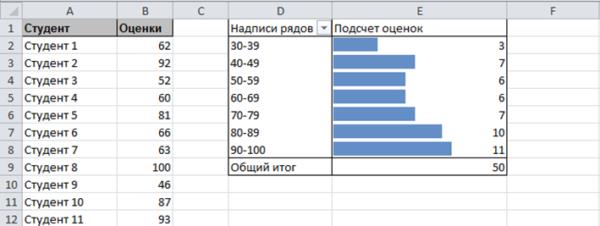
Применение сводной таблицы для создания гистограммы частот
Если данные представлены в табличном виде, гистограмму частот можно создать с помощью сводной таблицы. На рисунке показаны данные успеваемости студентов, обобщенные в сводной таблице. Полосы данных добавлены с помощью средств условного форматирования.
Применение настраиваемых уровней дискретизации для создания гистограмм
На рисунке показан рабочий лист, в котором в столбце В (диапазон Баллы) перечислены оценки студентов (общее количество студентов – 67 человек). Столбцы D и Е содержат формулы, которые вычисляют верхние и нижние пределы интервалов на основе данных ячейки Е1 (диапазон РазмерыИнтервалов). Например, если ячейка РазмерыИнтервалов содержит значение 10, то каждый следующий элемент будет отстоять от предыдущего на 10 единиц (1-10, 11-20 и т.д.).
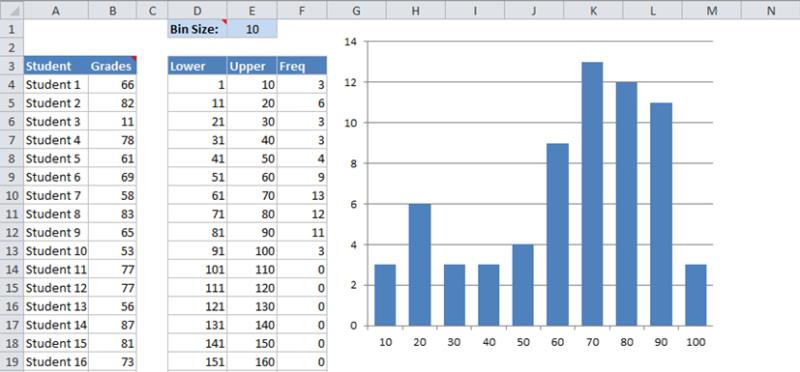
Данная диаграмма использует в формуле РЯД два динамических имени. Имя Категории определяется с помощью следующей формулы:
=СМЕЩ(Лист1!$Е$4;0;0;ОКРУГЛВВЕРХ(100/РазмерыИнтервалов;0))
Имя Частота определяется следующей формулой:
=СМЕЩ(Лист1!$F$4;0;0;ОКРУГЛВВЕРХ(100/РазмерыИнтервалов;0))
В результате при изменении содержимого ячейки РазмерыИнтервалов диаграмма автоматически корректируется.
В начало
Полезное